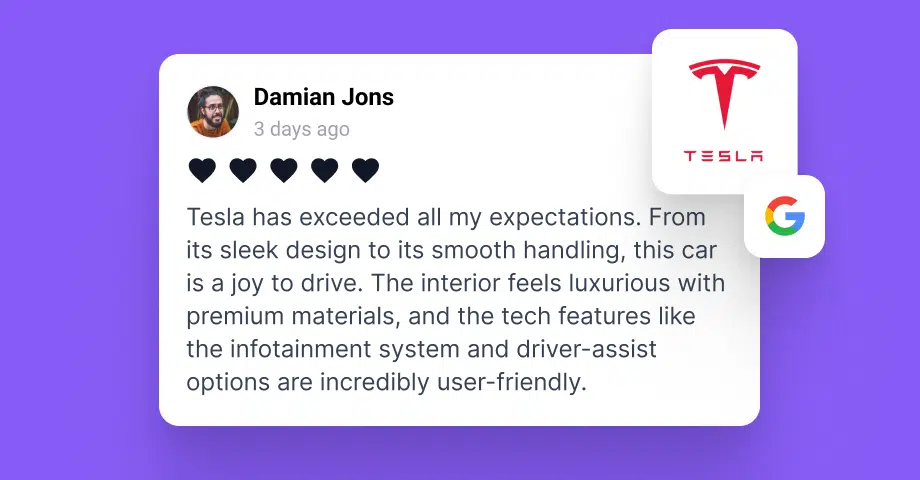
Na EmbedSocial, vejo sempre o mesmo padrão: As marcas estão rodeadas de provas dos clientes, mas os seus sítios Web continuam a basear-se em testemunhos obsoletos, capturas de ecrã manuais ou imagens desactualizadas feed das redes sociais que já não reflectem o que os clientes dizem atualmente.
É por isso que o debate entre a recolha de dados da Web e as API é tão importante no meu mundo.
No papel, ambos os métodos podem recolher dados online. Na prática, criam resultados muito diferentes quando o seu objetivo é publicar novas avaliações, UGCpor e provas sociais num sítio Web ativo.
Já vi equipas começarem com uma solução rápida, apenas para descobrirem que o verdadeiro desafio não é recolha de conteúdos gerados pelos utilizadores uma vez.
O verdadeiro desafio é agregar e incorporar publicações de redes sociais de forma fiável, moderando-os corretamente e utilizando-os para se tornarem mais fiáveis.
Bem, em seguida, explico o que é a recolha de dados da Web, mostro como funciona a recolha de dados da Web, explico a diferença entre a recolha de dados da Web e a API e explico por que razão a agregação social baseada na API, como A secção é normalmente o melhor modelo a longo prazo para as marcas.
Antes de começar, eis o resumo:

O que é a raspagem da Web?
Se alguém me perguntar o que é web scraping, a minha resposta mais simples é a seguinte:
É o processo de extração de informações visíveis de uma página Web e a sua conversão em dados estruturados. Um scraper visita uma página, lê o que é apresentado no HTML ou na interface processada, identifica os elementos que pretende e guarda essa informação num formato mais utilizável.
‘Definição de ’Web scraping
Essas informações podem incluir texto de avaliação, nomes de utilizador, legendas, classificações, detalhes de produtos, URLs de imagens, carimbos de data/hora ou outros dados de acesso público.
É por esta razão que a recolha de dados é popular em fluxos de trabalho que envolvem muita investigação. As empresas podem extrair dados para monitorização social da EmbedSocial casos de utilização, como o acompanhamento da concorrência, a análise de críticas públicas, o controlo de preços e, em alguns casos, raspagem da web dados das redes sociais.
Quero ser justo aqui: a raspagem não é inerentemente errada ou inútil.
É pode ser prático quando não existe uma API adequada, ou quando o objetivo é a análise interna e não a publicação orientada para o cliente.
O problema começa quando as equipas assumem que um método criado para extração é automaticamente bom para operações de conteúdo de sítios Web em curso.
Pela minha experiência, é aí que as coisas começam a falhar.
Como funciona a raspagem da Web?
A maior parte das explicações sobre o funcionamento do web scraping são demasiado abstractas. Penso que é muito mais claro quando se olha para ele como um processo passo-a-passo:

Passo 1: Pedir a página
Um scraper começa por enviar um pedido ao sítio Web de destino e recupera o conteúdo da página.
Em casos simples, isso significa descarregando HTML em bruto. Em casos mais difíceis, pode ser necessário processar JavaScript ou simular uma sessão do browser.
Passo 2: Localiza os elementos de destino
De seguida, o scraper procura na estrutura da página os dados de que necessita.
Pode basear-se em Selectores CSS, nomes de classes, IDs de elementos, caminhos XPath, ou componentes repetidos para encontrar os blocos de conteúdo corretos.
Passo 3: Extrai os campos de dados
Uma vez localizados os elementos alvo, o raspador extrai os campos úteis.
Isso pode incluir legendas, classificações, nomes de autores, hashtags, ligações aos media, datas, texto de revisão, ou outros atributos visíveis.
Etapa 4: Limpa e estrutura a saída
Os dados extraídos são muitas vezes confusos.
Assim, o próximo passo é normalizar as datas, remover caracteres extra, remodelar os campos e converter tudo num ficheiro formato estruturado como JSON ou CSV.
Passo 5: Repete o fluxo de trabalho à escala
Se o objetivo for a recolha contínua, o scraper é executado repetidamente em várias páginas, perfis, feeds ou URLs de origem. É aqui que começam a aparecer os encargos de manutenção.
Passo 6: Corrige o fluxo de trabalho quando a fonte muda
Um raspador depende da estrutura da página. Se a plataforma de origem alterar a forma como as legendas, miniaturas ou elementos da página são carregados, o fluxo de trabalho pode falhar. Essa falha pode ser insignificante num relatório interno, mas é muito mais grave quando o resultado aparece num sítio Web público.
Nesse caso, é necessário ajustar o raspador.
Exemplo da vida real:
Já vi um feed de conteúdos sociais funcionar perfeitamente nos testes e depois degradar-se silenciosamente após uma plataforma ter alterado a forma como os cartões multimédia eram processados. A equipa não perdeu apenas a qualidade dos dados. Acabaram por ter uma experiência de sítio Web deficiente.
O que é uma API?
Uma API, ou interface de programação de aplicações, é uma forma oficial de um sistema solicitar dados a outro num formato estruturado.
‘Definição de ’API
Esta definição parece técnica, mas a diferença prática é simples.
Com o scraping, lê-se o que aparece na página. Com uma API, o utilizador solicitar dados através de um canal criado para o acesso ao software.
Em vez de analisar o conteúdo visível do front-end, recebe dados estruturados diretamente de pontos finais definidos, frequentemente em JSON.
Normalmente, isso torna o fluxo de trabalho mais fácil de manter.
A os dados são mais limpos, a estrutura é mais previsível, e a integração é menos dependente do aspeto de uma página no browser.
É claro que as APIs não são perfeitas. Podem ter limites, aprovações, quotas e regras controladas pelo fornecedor sobre os dados que estão disponíveis.
Mas para fluxos de trabalho recorrentes, especialmente os que estão ligados a um sítio Web ativo, as API são normalmente uma base operacional muito mais sólida.
Web scraping vs API: as principais diferenças num ápice
Quando as pessoas pesquisam API vs. web scraping ou web scraping vs. API, normalmente querem uma comparação rápida e prática. Esta é a estrutura que utilizo com mais frequência:
| Raspagem da Web | API | |
|---|---|---|
| Fonte de dados | Conteúdo visível da página ou interface processada | Ponto final estruturado oficial |
| Formato dos dados | Em bruto ou semi-estruturado | Estruturado e mais fácil de integrar |
| Fiabilidade | Vulnerável a alterações de layout e renderização | Normalmente mais estável |
| Manutenção | Mais alto | Inferior |
| Clareza no cumprimento | Menos previsível | Normalmente mais claro |
| Flexibilidade | Elevado para páginas públicas | Limitado ao que o fornecedor expõe |
| Melhor ajuste | Investigação, controlo, extração pontual | Integrações repetíveis e fluxos de trabalho de publicação |
| Adequado para prova social em sítios Web | Frequentemente frágil | Normalmente muito melhor |
A verdadeira diferença entre a recolha de dados da Web e a API não é apenas a proveniência dos dados. É também o esforço que se faz após a recolha para manter o sistema utilizável, estável e pronto a ser publicado.
Prós e contras da recolha de dados da Web
Uma vez que uma das principais palavras-chave de apoio aqui é "prós e contras da raspagem da Web", quero mostrar claramente essa troca em vez de a simplificar demasiado.
| Profissionais da raspagem da Web | Contras da raspagem da Web |
|---|---|
| Pode recolher dados públicos mesmo quando não existe uma API | Quebras quando os layouts ou a renderização mudam |
| Altamente flexível e personalizável | Requer manutenção contínua |
| Útil para monitorização, investigação e escuta social | Pode enfrentar sistemas anti-bot e bloqueios |
| Menos dependente da disponibilidade da API do fornecedor | A formatação dos dados é frequentemente inconsistente |
| Útil para experiências ligeiras | Pode criar riscos políticos ou de governação, dependendo da utilização |
| Pode capturar campos visíveis que as APIs podem não expor | Fraca aptidão para experiências de sítios Web polidas e viradas para o cliente |
A minha opinião sincera é que o scraping é frequentemente mais forte quando o resultado é interno. Quando o resultado se torna público e sensível à marca, os pontos fracos tornam-se evidentes.
Vantagens da utilização de APIs
Se eu tivesse de resumir as principais vantagens da utilização de APIs para este caso de utilização:
- Dados mais limpos e estruturados-por exemplo, quando uma marca puxa e incorpora comentários do Google através de uma API, pode receber texto de críticas, classificações por estrelas, nomes de autores e carimbos de data/hora num formato previsível, em vez de os juntar a partir de elementos de página confusos;
- Menos dependência de layouts de front-end-Por exemplo, se uma plataforma social redesenhar os seus cartões de feed, uma ligação baseada em API pode continuar a funcionar porque se baseia no ponto de extremidade de dados subjacente e não na estrutura visível da página;
- Mais adequado para fluxos de trabalho repetíveis-Por exemplo, uma empresa com vários locais pode recolher automaticamente críticas recentes de dezenas de locais num único painel, em vez de verificar manualmente cada página, uma a uma;
- Apoio mais forte à frescura e à consistência-Por exemplo, uma marca de comércio eletrónico pode manter a página do produto widgets de revisão actualizados com comentários recentes de clientes, em vez de deixar os mesmos testemunhos estáticos durante meses;
- Regras de governação e de acesso mais claras-Por exemplo, uma equipa de marketing que utilize integrações oficiais tem muito mais facilidade em explicar de onde vem o conteúdo e como está a ser utilizado do que uma equipa que se baseie em páginas públicas extraídas;
- Menos limpeza e menos trabalhos de reparação mais tarde-Por exemplo, os programadores não têm de continuar a corrigir selectores danificados sempre que um site de origem altera a sua estrutura HTML ou a renderização de media;
- Um caminho mais fácil da recolha à publicação-Por exemplo, uma marca pode transferir a prova social de fontes ligadas para um carrossel de página inicial em direto ou para um widget de avaliação sem ter de recorrer a ferramentas de recolha de dados da Web pouco fiáveis.
Em suma, as API não ajudam apenas a recolher dados. Ajudam-no a construir um sistema em torno desses dados. A extração de dados torna-se um processo fiável que proporciona um acesso estruturado aos dados.
Além disso, as APIs permitem-lhe direcionar as páginas de um sítio Web para obter dados específicos em vez de extrair tudo dessas páginas e depois peneirar os conteúdos.
Porque é que os dados das redes sociais são diferentes dos dados gerais da Web?
A maior parte dos artigos genéricos sobre Web scraping e API tratam todos os dados online como se pertencessem ao mesmo saco. Pela minha experiência, é aí que a análise se torna demasiado superficial.
O conteúdo das redes sociais deixa de ser ‘apenas dados’ no momento em que aparece numa página inicial, numa página de produto ou num widget de avaliação. Nessa altura, passa a ser conteúdo gerador de confiança.
| Caso de utilização geral de dados da Web | Caso de utilização de dados das redes sociais |
|---|---|
| Frequentemente utilizado para análise interna | Frequentemente utilizado para provas dirigidas ao cliente |
| Podem ser aceites pequenos problemas de formatação | A formatação afecta diretamente a perceção |
| Um intervalo temporário pode ser inconveniente | Um feed quebrado pode prejudicar a confiança |
| Normalmente centrado na recuperação | Requer recuperação, moderação e publicação |
| Frequentemente em painéis de controlo ou relatórios | Vive em sítios Web, widgets e páginas de conversão |
| Menor risco de marca se for apenas interno | Maior risco de marca porque os clientes vêem-no |
É por isso que separo tão fortemente estes casos de utilização. Uma folha de cálculo pode tolerar resultados confusos. Uma folha de cálculo Widget UGC não pode. Não se trata apenas de extrair dados de páginas Web, mas de os reimplementar em widgets de sítios Web activos e geradores de confiança que se actualizam automaticamente.
Recolha de dados das redes sociais na Web: Onde é que isso falha?
O apelo da recolha de dados das redes sociais na Web é óbvio à primeira vista. O conteúdo público parece acessível, a configuração pode parecer rápida e as equipas podem pensar que encontraram um atalho.
Na prática, o modelo começa a falhar de forma previsível:
Alterações no front-end criam fragilidade
As plataformas sociais mudam frequentemente.
Um feed que dependa de uma estrutura de página visível pode deixar de funcionar quando uma legenda é carregada de forma diferente, um elemento multimédia é reestruturado ou a plataforma altera a forma como a interface é apresentada.
Dica profissional:
Nunca crie um feed voltado para o cliente com base apenas em suposições de layout de página. Se uma plataforma alterar a forma como as legendas, os cartões ou os suportes de dados são apresentados, o seu feed pode avariar de um dia para o outro. É por isso que o acesso oficial à API é normalmente a base mais segura para qualquer coisa que se destine ao público.
A qualidade da formatação torna-se difícil de controlar
Mesmo quando um "scraper" funciona tecnicamente, o resultado pode não ser adequado para publicação.
Já vi conteúdo social extraído de redes sociais com legendas em falta, má apresentação dos meios de comunicação social, esquemas de cartões desiguais e atribuição incompleta.
Dica profissional:
Um feed que “funciona tecnicamente” não é o mesmo que um feed que está pronto para publicação. Antes de o conteúdo ser publicado, certifique-se de que consegue controlar de forma fiável as legendas, a qualidade dos suportes, a atribuição, a consistência dos cartões e o comportamento de fallback em todos os layouts.
A moderação torna-se um fardo manual
Uma vez recolhido o conteúdo, alguém ainda tem de decidir o que deve ser efetivamente publicado.
Ou seja Gestão do UGC como a filtragem de spam, a remoção de mensagens irrelevantes, a exclusão de conteúdos de baixa qualidade e a verificação de que o resultado final continua a ser adequado à marca.
Dica profissional:
A recolha de conteúdos é apenas metade do trabalho. A verdadeira vitória operacional advém de ter fluxos de trabalho de gestão de CGU integrados para filtrar spam, remover mensagens irrelevantes, trazer à superfície o melhor conteúdo e manter cada widget alinhado com os padrões da sua marca.
A escala multiplica o custo de manutenção
Um alimento experimental é manejável.
Vários feeds em páginas de produtos, campanhas e sítios Web de clientes criam uma carga de manutenção muito diferente. A recolha de dados em grande escala necessita de acesso à API. Para obter dados fiáveis e em grande escala, é necessário ter acesso direto à disponibilidade dos dados.
Dica profissional:
Um feed experimental pode ser gerido com raspagem, mas a recolha de dados em grande escala é um jogo diferente. Quando é necessário um conteúdo fiável em várias páginas, campanhas ou sítios de clientes, o acesso direto a uma disponibilidade de dados estável é muito mais importante do que a velocidade de configuração a curto prazo.
A governação torna-se mais difícil de gerir
Dependendo da plataforma, do tipo de conteúdo e do caso de utilização, a recolha de dados pode levantar questões adicionais relacionadas com termos, privacidade, acesso e risco para a marca.
Para muitas equipas, essa incerteza, por si só, torna-a uma base fraca para a prova orientada para o cliente.
Dica profissional:
Se o conteúdo influenciar a confiança ou as decisões de compra, o método de recolha deve ser avaliado em função da fiabilidade e da governação, e não apenas pelo facto de poder obter os dados uma vez.
API direta vs API de agregação: qual é a diferença?
Esta é a distinção que a maioria dos artigos sobre API vs. raspagem da Web não faz. Muitas equipas pensam que a escolha é simplesmente entre a recolha de dados e a utilização de uma API.
Na realidade, a comparação mais útil é entre a recolha de dados, a integração direta da API e um sistema gerido de redes sociais camada.
| O que recebe | Principal inconveniente | Melhor ajuste | |
|---|---|---|---|
| Raspagem da Web | Acesso flexível a conteúdos públicos visíveis | Frágil, de manutenção pesada, confuso para publicação | Investigação, acompanhamento, experiências |
| Integração direta da API | Acesso oficial estruturado aos dados de origem | Continua a ser necessário criar uma lógica de moderação, sincronização, formatação e publicação | Equipas técnicas com recursos de desenvolvimento |
| API ou plataforma de agregação | Acesso oficial e ferramentas de fluxo de trabalho, moderação, organização e publicação | Menos controlo bruto do que os sistemas totalmente personalizados | Marcas, profissionais de marketing, agências, equipas de comércio eletrónico |
O acesso direto à API é poderoso. Mas muitas equipas subestimam o que vem depois da conetividade. Depois de ter os dados, continua a ser necessário gerir a fonte, as regras de moderação, a lógica de transformação, os ciclos de atualização, a geração de widgets, o controlo da disposição e a manutenção contínua.
É por isso que volto sempre ao mesmo ponto: o acesso em bruto não é o mesmo que uma conduta de prova social funcional. É necessário um redes sociais como o EmbedSocial.
Quando é que a recolha de dados da Web ainda faz sentido?
Não me parece que um artigo credível sobre raspagem da Web vs. API deva fingir que a raspagem não tem lugar. É verdade que tem. Um bom exemplo é monitorização social da EmbedSocial.
Se uma equipa quiser monitorizar conversas públicas, explorar discussões visíveis ou recolher dados para análise interna, a recolha de dados pode ser prática e eficiente.
Outro exemplo é o público de nicho recolha de dados.
Por vezes, as informações necessárias são públicas, mas não existe uma API útil. Nesses casos, a raspagem pode ser o único caminho realista para os dados.
Também acho que a raspagem pode fazer sentido para experiências internas ligeiras.
Se o fluxo de trabalho for temporário, se a equipa compreender a fragilidade e se não depender de nada para o cliente, a troca pode ser aceitável.
Mas assim que o conteúdo se torna parte da experiência pública da marca, normalmente aconselho as equipas a elevar o nível. É aí que o scraping começa muitas vezes a tornar-se uma responsabilidade.
Porque é que a agregação social baseada em API é o melhor sistema a longo prazo para as marcas?
É aqui que o caso comercial se torna muito mais claro. Um modelo de agregação baseado em API é melhor para as marcas porque resolve mais do que a recolha.
Ajuda a gerir o ciclo de vida completo do conteúdo após a recolha.
Tomemos como exemplo uma marca de comércio eletrónico em crescimento.
Pode querer avaliações recentes em páginas de produtos, UGC em páginas de destino e provas sociais na página inicial. Tentar manter isso por meio de soluções alternativas dispersas cria um problema muito rapidamente. A agregação centralizada e baseada em API torna esse sistema gerenciável.
Uma empresa de serviços é outro bom exemplo.
Substituir as capturas de ecrã de testemunhos estáticos por conteúdo de avaliações ao vivo pode tornar o sítio mais atual, mais credível e mais alinhado com o que os clientes estão a dizer neste momento. Imagine um muro do amor página no seu sítio Web que se actualiza automaticamente.
Também me interessa a quantidade de trabalho que um sistema cria nos bastidores. Um bom fluxo de trabalho reduz as capturas de ecrã, a curadoria manual, os pedidos repetitivos dos programadores e as correcções de emergência.
Exemplo do meu trabalho na EmbedSocial:
Já vi empresas substituírem um bloco de testemunhos desatualizado por um fluxo em direto de avaliações recentes do Google e menções sociais. O resultado não foi apenas um conteúdo mais atual. O sítio pareceu mais ativo, mais atual e mais credível.
Como é que a EmbedSocial transforma a prova social num ativo vivo do website?
Esta é a parte que conheço mais diretamente por experiência prática.
Em EmbedSocial, O objetivo não é apenas ajudar as marcas a recolher conteúdos. O objetivo é ajudá-las a transformar o conteúdo real dos clientes em algo organizado, moderado e pronto a ser publicado.
Aqui está um gráfico simples que cobre o processo de agregação de conteúdos das redes sociais:

Eis os passos a seguir criar a sua conta EmbedSocial:
Passo 1: Apresentar um pedido de conceção de widget de IA
Em primeiro lugar, tem de pedir ao editor de widgets de IA que crie o seu novo widget de redes sociais:

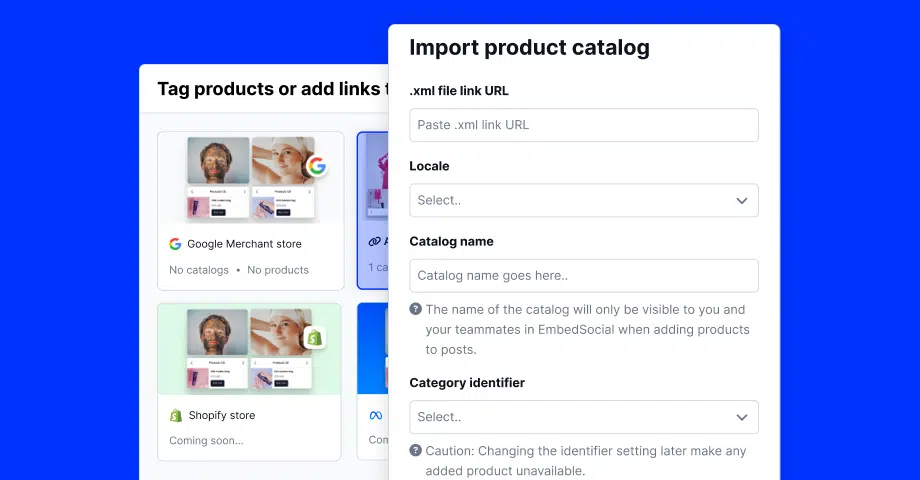
Passo 2: Ligar a(s) sua(s) fonte(s) de redes sociais
Depois, tem de se ligar às suas redes sociais para extrair o seu conteúdo no EmbedSocial:

Passo 3: Desenhe e personalize o seu widget
Em seguida, pode selecionar o seu modelo de widget e personalizá-lo através de prompts de IA:

Se não estiver satisfeito com o aspeto do widget, basta navegar para o design de IA e adicionar mais avisos:

Passo 4: Moderar o conteúdo do widget
Dirija-se ao Moderação avançada para selecionar mensagens específicas que pretende apresentar:

Passo 5: Publicar os widgets no sítio Web
Quando o widget ou o feed estiver pronto, é necessário copiar o respetivo código incorporável através do botão Dê vida ao seu tab:

Passo 6: Colar o código do widget no seu sítio Web
A última coisa que precisa de fazer é navegar para o seu construtor de sítios Web e colar o código do widget.
Eis como isso funciona em todos os construtores de sítios Web populares:
Como incorporar UGC no WordPress?
Eis como incorporar UGC em sítios WordPress:
- Depois de criar o widget EmbedSocial, aceda à sua página de administração do WordPress;
- Inicie sessão na sua conta e abra a página onde pretende adicionar o widget UGC;
- Clique no botão + no editor e selecionar HTML personalizado para colar o código do widget;
- Clique "Salvar" quando tiver terminado.

Como incorporar UGC na Shopify?
Veja como incorporar UGC em sites da Shopify:
- Inicie sessão na sua conta Shopify depois de copiar o código do widget incorporável no EmbedSocial;
- Navegar para o 'Páginas' e depois em 'Adicionar página';
- No separador 'Conteúdo' páginas de campo o código incorporável;
- Selecione a página onde pretende que o código apareça e prima "Guardar.

Como incorporar UGC no Squarespace?
Eis como incorporar UGC em sítios Squarespace:
- Copie o código do widget EmbedSocial e inicie sessão na sua conta Squarespace;
- Escolha a página onde pretende que as críticas apareçam;
- Clique em 'Adicionar nova secção' e depois 'Adicionar bloco' onde pretende apresentar o widget;
- Na lista de blocos, selecionar 'Incorporar‘;
- Clique no bloco, selecione ‘Trecho de código", e clicar em ‘Incorporar dados";
- Por fim, na caixa de código, cole o código de revisão copiado;
- Certifique-se de que guarda e publica as suas alterações no Squarespace.

Como incorporar UGC no Wix?
Veja como incorporar UGC em sites Wix:
- Inicie sessão no seu editor Wix e escolha a página e a localização para adicionar o widget;
- Clique no botão Ícone "+" no canto superior esquerdo para adicionar um novo elemento;
- Encontrar o Incorporar e Social secção e toque em 'Código de incorporação';
- Colar o código e tocar em 'Atualizar'.

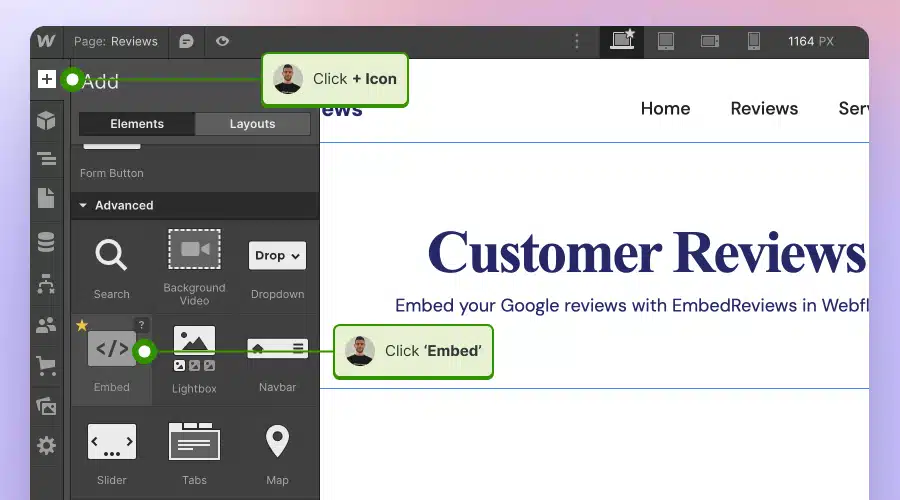
Como incorporar CGU no Webflow?
Eis como incorporar UGC em sítios Webflow:
- Depois de criar o widget no EmbedSocial, inicie sessão na sua conta Webflow;
- Aceda à vista de edição do seu sítio Web no Webflow;
- Escolher 'Adicionar elemento' no Webflow e selecione a opção Elemento "incorporar;
- Arraste e largue-o onde pretende que as suas críticas apareçam;
- No campo de introdução, cole o código EmbedSocial copiado.
Como incorporar UGC no Pagecloud?
Eis como incorporar UGC em sítios Pagecloud:
- Depois de copiar o código EmbedSocial, inicie sessão no seu Nuvem de páginas conta;
- Comece a editar a página Web onde pretende que as críticas apareçam;
- Toque em 'Aplicações' no menu da faixa de opções à esquerda e selecionar "Incorporar;
- Cole o código EmbedSocial no campo pop-up e clique em 'Ok' para concluir o processo.

Como incorporar UGC no Google Sites?
Veja como incorporar UGC no Google Sites:
- Depois de copiar o código do widget incorporável no EmbedSocial, faça login na sua conta do Google Sites;
- Navegue até à página onde pretende incorporar o widget;
- Utilizar o Separador "Inserir no Google Sites e escolha o local onde pretende colocar o widget;
- Selecione 'Dê vida ao seu' no menu e cole o código copiado na caixa de diálogo;
- Clique em 'Seguinte' e depois 'Inserir' para finalizar a incorporação.

Como incorporar UGC no Elementor?
Eis como incorporar UGC no Elementor:
- Inicie sessão e navegue até à página onde pretende adicionar as críticas;
- Toque numa secção vazia e escolha a opção Bloco "HTML na secção esquerda da faixa de opções;
- Arraste e largue-o na página e cole o código do widget no campo vazio;
- Actualize e publique a página para ver o widget em direto.

Como incorporar o UGC no Notion?
Veja como incorporar UGC no Notion:
- Depois de copiar o código do widget, iniciar sessão no Notione ir para a página correspondente;
- Digite o /embed e, no menu pendente, seleccione a opção Opção "Incorporar;
- Cole o URL e clique em "Incorporar ligação para adicionar os seus comentários a Notion.

Como incorporar UGC em sítios Web HTML?
Eis como incorporar UGC em sítios HTML
- Copie a revisão do widget EmbedSocial do ficheiro Separador "Incorporar" no canto superior esquerdo do Editor;
- Abra o ficheiro HTML do seu sítio Web, que pode ser uma nova página ou uma já existente;
- Cole o código de incorporação do EmbedSocial copiado onde pretende que as críticas sejam apresentadas.

Conclusão: Utilize plataformas UGC com acesso à API para criar um fluxo de trabalho fiável de prova social!
A razão pela qual a questão da recolha de dados da Web versus API continua a ser tão comum é simples: ambos os métodos podem ajudar a recolher dados online. Mas, para as marcas, esse enquadramento ainda é demasiado restrito.
A melhor questão é como transformar o conteúdo das redes sociais numa experiência estável, fiável e orientada para o cliente que mantenha o sítio Web atualizado ao longo do tempo.
Na minha perspetiva, o scraping ainda tem lugar na investigação, monitorização e análise exploratória. Mas quando o objetivo é publicar provas sociais num site ativo, um fluxo de trabalho de agregação baseado em API é normalmente a resposta mais inteligente a longo prazo.
Esta abordagem dá-lhe mais do que acesso.
Oferece-lhe estrutura, moderação, consistência e um caminho realista desde o conteúdo disperso do cliente até aos widgets do sítio Web que realmente criam confiança.
Perguntas frequentes sobre a recolha de dados da Web e a API para conteúdos das redes sociais
Qual é a diferença entre utilizar uma API e a raspagem da Web?
A principal diferença entre a recolha de dados da Web e a API é a forma como os dados são acedidos.
A raspagem da Web extrai informações do que aparece numa página Web, enquanto uma API fornece dados estruturados através de um ponto de acesso oficial concebido para a integração de software.
A utilização de uma API é melhor do que a raspagem da Web?
Quando as equipas comparam a recolha de dados da API com a recolha de dados da Web, a resposta depende do caso de utilização.
Para investigação ou monitorização pontual, a recolha de dados pode fazer sentido. Para fluxos de trabalho repetitivos e conteúdos de sítios Web virados para o cliente, as API são normalmente a melhor opção.
O que é a raspagem da Web em termos simples?
Se tivesse de responder numa frase o que é o web scraping, diria que é o processo de recolha automática de informações visíveis de páginas Web e a sua transformação em dados estruturados.
É por isso que é frequentemente utilizado em fluxos de trabalho de monitorização, recolha de dados públicos e investigação.
Como funciona a raspagem da Web, passo a passo?
A um nível básico, o funcionamento da raspagem da Web segue uma sequência.
Um scraper solicita uma página, lê o HTML ou o conteúdo processado, identifica os elementos de destino, extrai os campos necessários e guarda-os num formato estruturado, como JSON ou CSV.
Quais são os prós e os contras da raspagem da Web?
Os principais prós e contras da recolha de dados da Web resumem-se à flexibilidade versus fiabilidade.
A raspagem é flexível porque pode recolher dados públicos mesmo quando não existe uma API, mas também é mais frágil, exige mais manutenção e, normalmente, é menos adequada para experiências de sítios Web viradas para o cliente.
Quais são as principais vantagens da utilização de APIs?
As principais vantagens da utilização de APIs são a estrutura, a consistência e a repetibilidade.
Normalmente, as API devolvem dados mais limpos, são menos dependentes de alterações na página de front-end e são mais fáceis de ligar a fluxos de trabalho a longo prazo.
É possível utilizar a recolha de dados da Web para obter dados das redes sociais?
Sim, a recolha de dados das redes sociais na Web é possível em algumas situações.
Mas, pela minha experiência, é muito menos fiável quando o objetivo é publicar esse conteúdo num sítio Web ativo, onde a formatação, a atualidade e a moderação são importantes.
Porque é que os feeds sociais raspados quebram com tanta frequência?
Os feeds raspados quebram frequentemente porque dependem da estrutura da página.
Se uma plataforma alterar a forma como as legendas, miniaturas, cartões multimédia ou outros elementos são processados, o raspador pode deixar de devolver dados completos ou consistentes.
Quando é que a recolha de dados da Web ainda faz sentido?
A raspagem da Web ainda faz sentido para investigação, escuta social, recolha de dados públicos e algumas experiências internas.
Sou muito mais cauteloso a recomendá-lo quando o conteúdo se destina a uma experiência de marca virada para o cliente.
Qual é a diferença entre uma API direta e uma plataforma de agregação?
Uma API direta dá-lhe acesso bruto aos dados de origem.
Uma plataforma de agregação pega nesse acesso e transforma-o num fluxo de trabalho utilizável, ajudando-o a recolher, moderar, organizar e publicar conteúdos em várias fontes.
Posso apresentar o conteúdo das redes sociais no meu sítio Web sem fazer scraping?
Sim.
De facto, para a maioria das marcas, esse é o melhor caminho. Um fluxo de trabalho de agregação baseado em API permite-lhe recolher provas sociais através de ligações oficiais e publicá-las através de widgets, carrosséis, galerias ou feeds de avaliação, sem depender de métodos de raspagem frágeis.
A raspagem da Web é mais barata do que as API?
Nem sempre.
À partida, a recolha de dados pode parecer mais barata, mas os encargos de manutenção a longo prazo alteram frequentemente o panorama dos custos, uma vez que são adicionadas as correcções, a monitorização, os problemas de formatação e as quebras de serviço ao público.
A agregação de redes sociais baseada em API é melhor para as marcas?
Para a maioria das marcas, sim.
Quando o objetivo é manter um sítio Web atualizado com conteúdos fiáveis dos clientes, a agregação baseada em API é normalmente o melhor sistema a longo prazo, porque suporta a recolha, a moderação e a publicação num único fluxo de trabalho.