En EmbedSocial, veo el mismo patrón una y otra vez: Las marcas están rodeadas de pruebas de clientes y, sin embargo, sus sitios web siguen basándose en testimonios anticuados, capturas de pantalla manuales u obsoletas. en redes sociales que ya no reflejan lo que dicen los clientes hoy en día.
Por eso el debate entre web scraping y API es tan importante en mi mundo.
Sobre el papel, ambos métodos permiten recopilar datos en línea. En la práctica, los resultados son muy diferentes cuando el objetivo es publicar reseñas recientes, UGCy Recoge, gestiona y publica contenido generado por usuarios (UGC) en un sitio web activo.
He visto a equipos empezar con una solución rápida, sólo para descubrir que el verdadero reto no es recopilación de contenidos generados por los usuarios una vez.
El verdadero reto es agregar y incrustación de publicaciones en redes sociales de forma fiable, moderarlas adecuadamente y utilizarlas para ser más dignos de confianza.
A continuación, explico qué es el web scraping, cómo funciona, la diferencia entre web scraping y API, y por qué la agregación social basada en API como EmbedSocial suele ser el mejor modelo a largo plazo para las marcas.
Antes de entrar en materia, he aquí el resumen:

¿Qué es el web scraping?
Si alguien me pregunta qué es el web scraping, mi respuesta más sencilla es la siguiente:
Es el proceso de extraer información visible de una página web y convertirla en datos estructurados. Un scraper visita una página, lee lo que se muestra en la interfaz HTML o renderizada, identifica los elementos que desea y guarda esa información en un formato más utilizable.
‘Definición de ’Web scraping
Esa información puede incluir texto de reseñas, nombres de usuario, pies de foto, valoraciones, detalles de productos, URL de imágenes, marcas de tiempo u otros datos de acceso público.
Por eso el scraping es tan popular en los flujos de trabajo intensivos en investigación. Las empresas pueden extraer datos para monitorización social de EmbedSocial casos de uso, como el seguimiento de la competencia, el análisis de la opinión pública, el control de precios y, en algunos casos, web scraping datos de redes sociales.
Quiero ser justo en este punto: el raspado no es intrínsecamente malo o inútil.
En puede ser práctico cuando no existe una API adecuada, o cuando el objetivo es el análisis interno y no la publicación de cara al cliente.
El problema comienza cuando los equipos asumen que un método creado para la extracción es automáticamente bueno para las operaciones continuas de contenido de un sitio web.
Según mi experiencia, ahí es donde las cosas empiezan a romperse.
¿Cómo funciona el web scraping?
La mayoría de las explicaciones sobre cómo funciona el web scraping son demasiado abstractas. Creo que es mucho más claro cuando se ve como un proceso paso a paso:

Paso 1: Solicita la página
Un scraper envía primero una solicitud al sitio web de destino y recupera el contenido de la página.
En casos sencillos, eso significa descargar HTML en bruto. En casos más difíciles, puede ser necesario renderizar JavaScript o simular una sesión de navegador.
Paso 2: Localiza los elementos objetivo
A continuación, el scraper escanea la estructura de la página en busca de los datos que necesita.
Puede basarse en selectores CSS, nombres de clase, ID de elementos, rutas XPath, o componentes repetidos para encontrar los bloques de contenido adecuados.
Paso 3: Extrae los campos de datos
Una vez localizados los elementos objetivo, el rascador extrae los campos útiles.
Esto puede incluir subtítulos, clasificaciones, nombres de autor, hashtags, enlaces multimedia, fechas, texto de revisión, u otros atributos visibles.
Paso 4: Limpia y estructura la salida
Los datos raspados suelen estar desordenados.
Así que el siguiente paso es normalizar las fechas, eliminar los caracteres sobrantes, remodelar los campos y convertirlo todo en un archivo formato estructurado como JSON o CSV.
Paso 5: Repite el flujo de trabajo a escala
Si el objetivo es la recopilación continua, el scraper se ejecuta repetidamente en múltiples páginas, perfiles, feeds o URL de origen. Aquí es donde empieza a aparecer la carga del mantenimiento.
Paso 6: Corrige el flujo de trabajo cuando cambia la fuente
Un scraper depende de la estructura de la página. Si la plataforma de origen cambia la forma en que se cargan los pies de foto, las miniaturas o los elementos de la página, el flujo de trabajo puede fallar. Ese fallo puede ser menor en un informe interno, pero es mucho más grave cuando el resultado aparece en un sitio web público.
En tal caso, hay que ajustar el rascador.
Un ejemplo de la vida real:
He visto cómo un feed de contenido social funcionaba perfectamente en las pruebas y luego se degradaba silenciosamente después de que una plataforma cambiara el modo de representación de las tarjetas multimedia. El equipo no sólo perdió calidad de datos. Terminaron con una experiencia de sitio web rota.
¿Qué es una API?
Una API, o interfaz de programación de aplicaciones, es una forma oficial de que un sistema solicite datos a otro en un formato estructurado.
‘Definición de ’API
Esa definición suena técnica, pero la diferencia práctica es sencilla.
Con el scraping, se lee lo que aparece en la página. Con una API solicitar datos a través de un canal construido para el acceso de software.
En lugar de analizar el contenido visible del front-end, recibe datos estructurados directamente de los puntos finales definidos, a menudo en JSON.
Esto suele facilitar el mantenimiento del flujo de trabajo.
La función de los datos son más limpios, la estructura es más predecible, y la integración depende menos del aspecto de la página en el navegador.
Por supuesto, las API no son perfectas. Pueden tener límites, aprobaciones, cuotas y reglas controladas por el proveedor sobre qué datos están disponibles.
Pero para los flujos de trabajo recurrentes, especialmente los vinculados a un sitio web activo, las API suelen ser una base operativa mucho más sólida.
Web scraping vs API: las principales diferencias de un vistazo
Cuando la gente busca API frente a web scraping o web scraping frente a API, suele querer una comparación rápida y práctica. Este es el marco que utilizo con más frecuencia:
| Web scraping | API | |
|---|---|---|
| Fuente de datos | Contenido visible de la página o interfaz renderizada | Punto final estructurado oficial |
| Formato de los datos | En bruto o semiestructurado | Estructurado y más fácil de integrar |
| Fiabilidad | Vulnerable a los cambios de diseño y renderizado | Suele ser más estable |
| Mantenimiento | Más alto | Baja |
| Claridad en el cumplimiento | Menos previsible | Normalmente más claro |
| Flexibilidad | Alta para páginas públicas | Limitado a lo que expone el proveedor |
| Mejor ajuste | Investigación, seguimiento, extracción puntual | Integraciones y flujos de trabajo de publicación repetibles |
| Adecuado para la prueba social en sitios web | A menudo frágil | Normalmente mucho mejor |
La verdadera diferencia entre el web scraping y la API no es sólo de dónde proceden los datos. También es el esfuerzo que hay que hacer después de la recopilación para mantener el sistema utilizable, estable y listo para su publicación.
Pros y contras del web scraping
Dado que una de las principales palabras clave de apoyo aquí es pros y contras del web scraping, quiero mostrar ese equilibrio claramente en lugar de simplificarlo en exceso.
| Profesionales del raspado web | Contras del "scraping |
|---|---|
| Puede recoger datos públicos aunque no exista API | Interrupciones al cambiar el diseño o el renderizado |
| Altamente flexible y personalizable | Requiere un mantenimiento continuo |
| Útil para el seguimiento, la investigación y la escucha social | Puede enfrentarse a sistemas anti-bot y de bloqueo |
| Menos dependiente de la disponibilidad de la API del proveedor | El formato de los datos suele ser incoherente |
| Útil para experimentos ligeros | Puede crear riesgos políticos o de gobernanza en función de su uso |
| Puede capturar campos visibles que las API no exponen | Poca adecuación a las experiencias web de cara al cliente |
Mi opinión sincera es que el scraping suele ser más eficaz cuando los resultados son internos. Una vez que el resultado se hace público y sensible a la marca, los puntos débiles se hacen evidentes.
Ventajas del uso de API
Si tuviera que resumir las principales ventajas de utilizar API para este caso de uso:
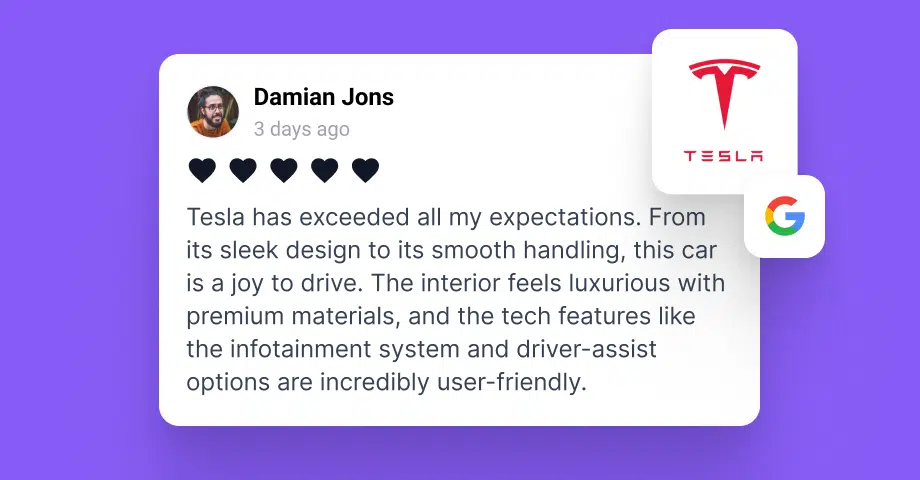
- Datos más limpios y estructurados-por ejemplo, cuando una marca tira y incrusta reseñas de Google a través de una API, puede recibir el texto de las reseñas, las puntuaciones con estrellas, los nombres de los autores y las marcas de tiempo en un formato predecible, en lugar de reunirlos a partir de elementos desordenados de la página;
- Menos dependencia de los diseños frontales-por ejemplo, si una plataforma social rediseña sus tarjetas de alimentación, una conexión basada en API puede seguir funcionando porque se basa en el punto final de datos subyacente y no en la estructura visible de la página;
- Mejor adaptación a los flujos de trabajo repetibles-Por ejemplo, una empresa con varias sedes puede recopilar automáticamente opiniones recientes de docenas de ubicaciones en un panel de control en lugar de comprobar manualmente cada página una por una;
- Mayor apoyo a la frescura y la coherencia-por ejemplo, una marca de comercio electrónico puede mantener la página de productos widgets de revisión actualizados con opiniones recientes de los clientes en lugar de dejar los mismos testimonios estáticos durante meses;
- Gobernanza y normas de acceso más claras-Por ejemplo, a un equipo de marketing que utilice integraciones oficiales le resultará mucho más fácil explicar de dónde proceden los contenidos y cómo se utilizan que a un equipo que se base en páginas públicas raspadas;
- Menos limpieza y menos reparaciones posteriores-por ejemplo, los desarrolladores no tienen que seguir arreglando selectores rotos cada vez que un sitio fuente cambia su estructura HTML o la representación de medios;
- Un camino más fácil de la recogida a la publicación-por ejemplo, una marca puede trasladar pruebas sociales de fuentes conectadas a un carrusel de la página de inicio en directo o a un widget de reseñas sin tener que coser herramientas de raspado web poco fiables.
En resumen, las API no sólo le ayudan a recopilar datos. Le ayudan a construir un sistema en torno a esos datos. La extracción de datos se convierte en un proceso fiable que proporciona un acceso estructurado a los datos.
Además, las API permiten seleccionar páginas del sitio web para obtener datos específicos en lugar de extraer todo el contenido de dichas páginas y filtrarlo después.
¿Por qué los datos de las redes sociales son diferentes de los datos generales de la web?
La mayoría de los artículos genéricos sobre web scraping frente a API tratan todos los datos en línea como si pertenecieran a la misma categoría. Según mi experiencia, ahí es donde el análisis se vuelve demasiado superficial.
Los contenidos de las redes sociales dejan de ser ‘sólo datos’ en el momento en que aparecen en una página de inicio, una página de producto o un widget de reseñas. En ese momento, se convierte en un contenido que genera confianza.
| Caso general de uso de datos web | Caso práctico de datos de redes sociales |
|---|---|
| A menudo se utiliza para análisis internos | A menudo se utiliza para pruebas de cara al cliente |
| Pueden aceptarse pequeños problemas de formato | El formato afecta directamente a la percepción |
| Un vacío temporal puede ser inconveniente | Un feed roto puede dañar la confianza |
| Suele centrarse en la recuperación | Requiere recuperación, moderación y publicación |
| A menudo vive en cuadros de mando o informes | Vive en sitios web, widgets y páginas de conversión |
| Menor riesgo para la marca si sólo es interna | Mayor riesgo de marca porque los clientes lo ven |
Por eso separo tanto estos casos de uso. Una hoja de cálculo puede tolerar un resultado desordenado. Una Widget UGC no puede. No se limita a extraer datos de las páginas web, sino que los reimplanta en widgets de sitios web vivos que generan confianza y se actualizan automáticamente.
Web scraping de datos de redes sociales: ¿Dónde se rompe?
Al principio, el atractivo del web scraping de datos de redes sociales es obvio. El contenido público parece accesible, la configuración puede parecer rápida y los equipos pueden creer que han encontrado un atajo.
En la práctica, el modelo empieza a quebrarse de forma previsible:
Los cambios en el front-end crean fragilidad
Las plataformas sociales cambian a menudo.
Un feed que depende de la estructura visible de la página puede dejar de funcionar cuando un pie de foto se carga de forma diferente, un elemento multimedia se reestructura o la plataforma cambia la forma de renderizar la interfaz.
Consejo profesional:
Nunca construyas un feed orientado al cliente basándote únicamente en suposiciones sobre el diseño de la página. Si una plataforma cambia el modo en que se muestran los pies de foto, las tarjetas o el contenido multimedia, el feed puede romperse de la noche a la mañana.
La calidad del formato es difícil de controlar
Incluso cuando un scraper funciona técnicamente, el resultado puede no ser apto para su publicación.
He visto contenido social raspado con subtítulos faltantes, mala representación de los medios, diseños de tarjetas desiguales y atribución incompleta.
Consejo profesional:
Un feed que “técnicamente funciona” no es lo mismo que un feed listo para publicar. Antes de publicar el contenido, asegúrate de que puedes controlar de forma fiable los subtítulos, la calidad de los medios, la atribución, la coherencia de las tarjetas y el comportamiento de los archivos de reserva en todos los diseños.
La moderación se convierte en una carga manual
Una vez recopilados los contenidos, alguien tiene que decidir qué es lo que debe publicarse.
Es decir Gestión de UGC como filtrar el spam, eliminar las entradas irrelevantes, excluir los contenidos de baja calidad y comprobar si el resultado final sigue siendo acorde con la marca.
Consejo profesional:
La recopilación de contenidos es sólo la mitad del trabajo. La verdadera ventaja operativa es disponer de flujos de trabajo de gestión del contenido generado por el usuario integrados para filtrar el spam, eliminar las publicaciones irrelevantes, sacar a la luz los mejores contenidos y mantener cada widget alineado con los estándares de la marca.
La escala multiplica el coste de mantenimiento
Un pienso experimental es manejable.
Múltiples feeds a través de páginas de productos, campañas y sitios web de clientes crean una carga de mantenimiento muy diferente. La recopilación de datos a gran escala necesita acceso a la API. Si quieres obtener datos fiables a gran escala, necesitas acceso directo a la disponibilidad de los datos.
Consejo profesional:
Un feed experimental puede ser manejable con scraping, pero la recopilación de datos a gran escala es un juego diferente. Cuando se necesitan contenidos fiables en varias páginas, campañas o sitios web de clientes, el acceso directo a datos estables es mucho más importante que la velocidad de configuración a corto plazo.
La gobernanza es cada vez más difícil de gestionar
Dependiendo de la plataforma, el tipo de contenido y el caso de uso, el scraping puede plantear cuestiones adicionales sobre las condiciones, la privacidad, el acceso y el riesgo para la marca.
Para muchos equipos, esa incertidumbre por sí sola constituye una base débil para la prueba de cara al cliente.
Consejo profesional:
Si el contenido va a influir en la confianza o en las decisiones de compra, el método de recopilación debe juzgarse por su fiabilidad y gobernanza, no sólo por si puede extraer los datos una sola vez.
API directa frente a API de agregación: ¿cuál es la diferencia?
Esta es la distinción que la mayoría de los artículos sobre API frente a web scraping pasan por alto. Muchos equipos piensan que la elección es simplemente entre el scraping y el uso de una API.
En realidad, la comparación más útil es entre el scraping, la integración directa de la API y un sistema gestionado de plataforma social capa.
| Lo que obtiene | Principal inconveniente | Mejor ajuste | |
|---|---|---|---|
| Web scraping | Acceso flexible a contenidos públicos visibles | Frágil, pesado de mantener, complicado de publicar | Investigación, seguimiento, experimentos |
| Integración directa en la API | Acceso estructurado oficial a los datos de origen | Todavía tienes que crear una lógica de moderación, sincronización, formateo y publicación. | Equipos técnicos con recursos de desarrollo |
| API o plataforma de agregación | Acceso oficial y herramientas de flujo de trabajo, moderación, organización y publicación | Menos control bruto que los sistemas totalmente personalizados | Marcas, vendedores, agencias, equipos de comercio electrónico |
El acceso directo a la API es potente. Pero muchos equipos subestiman lo que viene después de la conectividad. Una vez que se dispone de los datos, es necesario gestionar las fuentes, las reglas de moderación, la lógica de transformación, los ciclos de actualización, la generación de widgets, el control del diseño y el mantenimiento continuo.
Por eso vuelvo una y otra vez sobre el mismo punto: el acceso bruto no es lo mismo que un conducto de prueba social que funcione. Se necesita plataforma social como EmbedSocial.
¿Cuándo sigue teniendo sentido el web scraping?
No creo que un artículo creíble sobre web scraping frente a API deba pretender que el scraping no tiene cabida. Es absolutamente cierto. Un buen ejemplo es monitorización social de EmbedSocial.
Si un equipo desea supervisar conversaciones públicas, explorar debates visibles o recopilar datos para análisis internos, el scraping puede resultar práctico y eficaz.
Otro ejemplo son los nichos públicos recogida de datos.
A veces, la información necesaria es pública, pero no existe ninguna API útil. En esos casos, el scraping puede ser la única vía realista para acceder a los datos.
También creo que el raspado puede tener sentido para experimentos internos ligeros.
Si el flujo de trabajo es temporal, el equipo comprende su fragilidad y no depende de él nada de cara al cliente, la compensación puede ser aceptable.
Pero una vez que el contenido pasa a formar parte de la experiencia de marca pública, suelo aconsejar a los equipos que eleven el nivel. Ahí es donde el scraping empieza a convertirse en un lastre.
¿Por qué la agregación social basada en API es el mejor sistema a largo plazo para las marcas?
Aquí es donde el argumento comercial resulta mucho más claro. Un modelo de agregación basado en API es mejor para las marcas porque resuelve algo más que la recopilación.
Ayuda a gestionar el ciclo de vida completo de los contenidos después de su recogida.
Tomemos como ejemplo una marca de comercio electrónico en expansión.
Es posible que desee reseñas recientes en las páginas de productos, CGU en las páginas de destino y pruebas sociales en la página de inicio. Tratar de mantener todo esto mediante soluciones dispersas crea problemas muy rápidamente. La agregación centralizada basada en API hace que el sistema sea manejable.
Un negocio de servicios es otro buen ejemplo.
Sustituir las capturas de pantalla estáticas de testimonios por contenido de reseñas en vivo puede hacer que el sitio parezca más actual, más creíble y más alineado con lo que los clientes están diciendo en ese momento. Imagínese muro del amor página de su sitio web que se actualiza automáticamente.
También me importa cuánto trabajo genera un sistema entre bastidores. Un buen flujo de trabajo reduce las capturas de pantalla, la revisión manual, los tickets de desarrollador repetitivos y las correcciones de emergencia.
Ejemplo de mi trabajo en EmbedSocial:
He visto a empresas sustituir un bloque de testimonios obsoleto por un flujo en directo de reseñas recientes de Google y menciones sociales. El resultado no fue sólo un contenido más fresco. El sitio parecía más activo, más actual y más creíble.
¿Cómo convierte EmbedSocial la prueba social en un activo vivo del sitio web?
Esta es la parte que conozco más directamente por experiencia práctica.
En EmbedSocial, El objetivo no es sólo ayudar a las marcas a recopilar contenidos. Se trata de ayudarles a convertir los contenidos reales de los clientes en algo organizado, moderado y listo para publicar.
He aquí un sencillo gráfico sobre el proceso de agregación de contenidos en las redes sociales:

Y estos son los pasos que tienes que dar después Crear una cuenta EmbedSocial:
Paso 1: Envíe una solicitud de diseño de widget de IA
En primer lugar, tienes que solicitar al editor de widgets de AI que cree tu nuevo widget de redes sociales:

Paso 2: Conecta tus redes sociales
A continuación, tienes que conectarte a tus redes sociales para extraer su contenido en EmbedSocial:

Paso 3: Diseña y personaliza tu widget
A continuación, puedes seleccionar tu plantilla de widget y personalizarla aún más a través de las indicaciones de AI:

Si no estás satisfecho con el aspecto del widget, sólo tienes que ir al diseño AI y añadir más indicaciones:

Paso 4: Modere el contenido de su widget
Visite la página Moderación flexible para seleccionar las entradas específicas que desea mostrar:

Paso 5: Publicar los widgets en el sitio web
Una vez que el widget o feed esté listo, tienes que copiar su código incrustable a través del botón Inserta ficha:

Paso 6: Pegue el código del widget en su sitio web
Lo último que tienes que hacer es ir a tu creador de sitios web y pegar el código del widget.
Así es como funciona en todos los creadores de sitios web populares:
¿Cómo incrustar UGC en WordPress?
A continuación se explica cómo incrustar UGC en sitios de WordPress:
- Una vez creado el widget EmbedSocial, ve a la página de administración de WordPress;
- Inicie sesión en su cuenta y abra la página en la que desea añadir el widget UGC;
- Haz clic en el botón + botón en el editor y seleccione HTML personalizado para pegar el código del widget;
- Pulsa "Guardar"cuando hayas terminado.

¿Cómo incrustar UGC en Shopify?
Aquí te explicamos cómo incrustar UGC en sitios de Shopify:
- Accede a tu cuenta de Shopify después de copiar el código del widget incrustable en EmbedSocial;
- Navegue hasta el Páginas y haz clic en Añadir página;
- En el Contenido el código incrustable;
- Seleccione la página en la que desea que aparezca el código y pulse Guardar.

¿Cómo incrustar UGC en Squarespace?
Aquí te explicamos cómo incrustar UGC en sitios Squarespace:
- Copia el código del widget EmbedSocial e inicia sesión en tu cuenta de Squarespace;
- Elija la página en la que desea que aparezcan las reseñas;
- Haz clic en Añadir nueva sección y luego Añadir bloque donde desea mostrar el widget;
- En la lista de bloques, seleccione 'Embed‘;
- Haga clic en el bloque, seleccione ‘Fragmento de código", y haz clic en ‘Incrustar datos";
- Por último, en el cuadro de código, pegue el código de revisión copiado;
- Asegúrate de guardar y publicar los cambios en Squarespace.

¿Cómo incrustar UGC en Wix?
Aquí te explicamos cómo incrustar UGC en sitios Wix:
- Accede a tu editor Wix y elige la página y la ubicación para añadir el widget;
- Haz clic en el botón Icono "+". en la esquina superior izquierda para añadir un nuevo elemento;
- Encuentra el Embed & Social y pulse Código de incrustación;
- Pegue el código y pulse Actualizar.

¿Cómo incrustar UGC en Webflow?
He aquí cómo incrustar UGC en los sitios Webflow:
- Después de crear el widget en EmbedSocial, inicie sesión en su cuenta Webflow;
- Vaya a la vista de edición de su sitio web dentro de Webflow;
- Elija Añadir elemento en Webflow y seleccione la opción Elemento "Embed;
- Arrástrelo y suéltelo donde quiera que aparezcan sus reseñas;
- En el campo de entrada, pegue el código EmbedSocial copiado.
¿Cómo incrustar UGC en Pagecloud?
He aquí cómo incrustar UGC en sitios Pagecloud:
- Después de copiar el código de EmbedSocial, inicia sesión en tu cuenta de Pagecloud cuenta;
- Comience a editar la página web en la que desea que aparezcan las reseñas;
- Desde tu perfil, pulsa Aplicaciones en el menú de la cinta de la izquierda y seleccione Incrustar;
- Pega el código de EmbedSocial en el campo emergente y haz clic en Ok para completar el proceso.

¿Cómo incrustar UGC en Google Sites?
A continuación te explicamos cómo incrustar contenido generado por los usuarios en Google Sites:
- Una vez que hayas copiado el código del widget incrustable en EmbedSocial, accede a tu cuenta de Google Sites;
- Navegue hasta la página en la que desea incrustar el widget;
- Utiliza el Pestaña "Insertar en Google Sites y elige dónde quieres colocar el widget;
- Elige 'Insertadel menú y pegue el código copiado en el cuadro de diálogo;
- Haz click enSiguientey despuésInserte' para finalizar la incrustación.

¿Cómo incrustar UGC en Elementor?
A continuación te explicamos cómo incrustar UGC en Elementor:
- Inicie sesión y navegue hasta la página en la que desea añadir las reseñas;
- Pulse una sección vacía y elija la opción Bloque "HTML de la sección izquierda de la cinta;
- Arrástrelo y suéltelo en la página y pegue el código del widget en el campo vacío;
- Actualice y publique la página para ver el widget en directo.

¿Cómo integrar UGC en Notion?
A continuación te explicamos cómo incrustar UGC en Notion:
- Después de copiar el código del widget, conectarse a Notiony vaya a la página correspondiente;
- Escriba el /embed y, en la lista desplegable, elija el comando Opción "incrustar;
- Pegue la URL y haga clic en "Incrustar enlace para añadir sus opiniones a Notion.

¿Cómo incrustar CGU en sitios web HTML?
Cómo incrustar CGU en sitios HTML
- Copie la reseña del widget EmbedSocial de la sección Pestaña "Incrustar en la esquina superior izquierda del Editor;
- Abra el archivo HTML de su sitio web, que puede ser una página nueva o una ya existente;
- Pega el código EmbedSocial copiado donde quieras que se muestren las opiniones.

Conclusión: Utiliza plataformas UGC con acceso a API para crear un flujo de trabajo de prueba social fiable.
La razón por la que el web scraping frente a la API sigue siendo una pregunta tan habitual es sencilla: ambos métodos pueden ayudar a recopilar datos en línea. Pero para las marcas, ese marco sigue siendo demasiado estrecho.
La mejor pregunta es cómo convertir el contenido de las redes sociales en una experiencia estable, fiable y de cara al cliente que mantenga el sitio web fresco a lo largo del tiempo.
Desde mi punto de vista, el scraping sigue teniendo cabida en la investigación, la supervisión y el análisis exploratorio. Pero cuando el objetivo es publicar pruebas sociales en un sitio web activo, un flujo de trabajo de agregación basado en API suele ser la respuesta más inteligente a largo plazo.
Ese planteamiento te da algo más que acceso.
Le ofrece estructura, moderación, coherencia y un camino realista desde el contenido disperso de los clientes hasta widgets de sitios web vivos que realmente generan confianza.
Preguntas frecuentes sobre web scraping y API para contenidos de redes sociales
¿Cuál es la diferencia entre utilizar una API y el web scraping?
La principal diferencia entre el web scraping y la API es cómo se accede a los datos.
El web scraping extrae información de lo que aparece en una página web, mientras que una API proporciona datos estructurados a través de un punto de acceso oficial diseñado para la integración de software.
¿Es mejor utilizar una API que el web scraping?
Cuando los equipos comparan la API con el web scraping, la respuesta depende del caso de uso.
Para la investigación o el seguimiento puntual, el scraping puede tener sentido. Para flujos de trabajo repetibles y contenidos de sitios web orientados al cliente, las API suelen ser la mejor opción.
¿Qué es el web scraping en términos sencillos?
Si tuviera que responder a qué es el web scraping en una frase, diría que es el proceso de recopilar automáticamente información visible de páginas web y convertirla en datos estructurados.
Por eso se utiliza a menudo en flujos de trabajo de vigilancia, recopilación de datos públicos e investigación.
¿Cómo funciona el web scraping paso a paso?
A un nivel básico, el funcionamiento del web scraping sigue una secuencia.
Un scraper solicita una página, lee el contenido HTML o renderizado, identifica los elementos objetivo, extrae los campos necesarios y los guarda en un formato estructurado como JSON o CSV.
¿Cuáles son los pros y los contras del web scraping?
Los principales pros y contras del web scraping se reducen a la flexibilidad frente a la fiabilidad.
El scraping es flexible porque puede recopilar datos públicos incluso cuando no existe una API, pero también es más frágil, requiere más mantenimiento y suele ser menos adecuado para las experiencias web orientadas al cliente.
¿Cuáles son las principales ventajas de utilizar API?
Las principales ventajas de utilizar API son la estructura, la coherencia y la repetibilidad.
Las API suelen devolver datos más limpios, dependen menos de los cambios en las páginas del front-end y son más fáciles de conectar a flujos de trabajo a largo plazo.
¿Se puede utilizar el web scraping para obtener datos de las redes sociales?
Sí, el web scraping de datos de redes sociales es posible en algunas situaciones.
Pero, según mi experiencia, es mucho menos fiable cuando el objetivo es publicar ese contenido en un sitio web activo, donde el formato, la frescura y la moderación son importantes.
¿Por qué se rompen tan a menudo las fuentes sociales raspadas?
Los feeds raspados a menudo se rompen porque dependen de la estructura de la página.
Si una plataforma cambia el modo en que se muestran los subtítulos, las miniaturas, las tarjetas multimedia u otros elementos, es posible que el scraper deje de devolver datos completos o coherentes.
¿Cuándo sigue teniendo sentido el web scraping?
El web scraping sigue teniendo sentido para la investigación, la escucha social, la recopilación de datos públicos y algunos experimentos internos.
Soy mucho más cauto a la hora de recomendarlo cuando el contenido está destinado a una experiencia de marca de cara al cliente.
¿Cuál es la diferencia entre una API directa y una plataforma de agregación?
Una API directa le ofrece acceso directo a los datos de origen.
Una plataforma de agregación toma ese acceso y lo convierte en un flujo de trabajo utilizable ayudándole a recopilar, moderar, organizar y publicar contenidos a través de múltiples fuentes.
¿Puedo mostrar contenidos de redes sociales en mi sitio web sin hacer scraping?
Sí.
De hecho, para la mayoría de las marcas, ese es el mejor camino. Un flujo de trabajo de agregación basado en API permite recopilar pruebas sociales a través de conexiones oficiales y publicarlas mediante widgets, carruseles, galerías o feeds de reseñas sin depender de frágiles métodos de scraping.
¿Es el web scraping más barato que las API?
No siempre.
El scraping puede parecer más barato al principio, pero la carga de mantenimiento a largo plazo suele cambiar el panorama de costes una vez que se añaden las correcciones, la supervisión, los problemas de formato y las roturas de cara al público.
¿Es mejor para las marcas la agregación de redes sociales basada en API?
Para la mayoría de las marcas, sí.
Cuando el objetivo es mantener un sitio web actualizado con contenidos fiables de los clientes, la agregación basada en API suele ser el mejor sistema a largo plazo, ya que admite la recopilación, moderación y publicación en un solo flujo de trabajo.