Chez EmbedSocial, je vois le même schéma encore et encore : Les marques sont entourées de preuves de leurs clients, mais leurs sites web s'appuient toujours sur des témoignages périmés, des captures d'écran manuelles, ou des flux de médias sociaux qui ne reflètent plus ce que les clients disent aujourd'hui.
C'est la raison pour laquelle le débat entre le web scraping et l'API est si important dans mon monde.
Sur le papier, les deux méthodes permettent de collecter des données en ligne. En pratique, elles produisent des résultats très différents lorsque votre objectif est de publier de nouvelles critiques, UGCet preuve sociale sur un site web en ligne.
J'ai vu des équipes commencer par trouver une solution rapide, avant de découvrir que le véritable défi n'était pas le suivant la collecte de contenu généré par les utilisateurs une fois.
Le véritable défi consiste à agréger et à intégrer des messages dans les médias sociaux Il s'agit d'un outil qui permet d'obtenir des informations fiables, de les modérer correctement et de les utiliser pour devenir plus digne de confiance.
Ci-dessous, j'explique ce qu'est le web scraping, je montre comment fonctionne le web scraping, je fais la différence entre le web scraping et l'API, et j'explique pourquoi l'agrégation sociale basée sur l'API, comme le Le site Web d'EmbedSocial est généralement le meilleur modèle à long terme pour les marques.
Avant d'entrer dans le vif du sujet, voici un résumé de la situation :

Qu'est-ce que le web scraping ?
Si quelqu'un me demande ce qu'est le web scraping, ma réponse la plus simple est la suivante :
Il s'agit d'extraire les informations visibles d'une page web et de les convertir en données structurées. Un scraper visite une page, lit ce qui est affiché dans l'interface HTML ou rendue, identifie les éléments qu'il veut et enregistre ces informations dans un format plus utilisable.
‘Définition du ’web scraping
Ces informations peuvent comprendre le texte des commentaires, les noms d'utilisateurs, les légendes, les évaluations, les détails des produits, les URL des images, les horodatages ou d'autres données accessibles au public.
C'est la raison pour laquelle le scraping est populaire dans les flux de travail à forte intensité de recherche. Les entreprises peuvent extraire des données pour écoute sociale Les applications sont nombreuses, comme le suivi des concurrents, l'analyse de l'opinion publique, la surveillance des prix et, dans certains cas, l'utilisation de l'Internet pour la gestion des déchets, web scraping données des médias sociaux.
Je tiens à être juste : le raclage n'est pas intrinsèquement mauvais ou inutile.
Il peut être pratique lorsqu'il n'existe pas d'API appropriée, ou lorsque l'objectif est une analyse interne plutôt qu'une publication orientée vers le client.
Le problème commence lorsque les équipes supposent qu'une méthode conçue pour l'extraction est automatiquement bonne pour les opérations courantes de contenu du site web.
D'après mon expérience, c'est là que les choses commencent à se gâter.
Comment fonctionne le web scraping ?
La plupart des explications sur le fonctionnement du web scraping restent trop abstraites. Je pense que c'est beaucoup plus clair lorsque l'on considère le processus étape par étape :

Étape 1 : Demande de la page
Un scraper envoie d'abord une requête au site web cible et récupère le contenu de la page.
Dans les cas simples, cela signifie télécharger du HTML brut. Dans les cas plus difficiles, il peut être nécessaire de rendre JavaScript ou de simuler une session de navigation.
Étape 2 : Localisation des éléments cibles
Ensuite, le scraper analyse la structure de la page pour y trouver les données dont il a besoin.
Il peut s'appuyer sur Sélecteurs CSS, noms de classes, ID d'éléments, chemins XPath, ou des composants répétés pour trouver les bons blocs de contenu.
Étape 3 : Extraction des champs de données
Une fois les éléments cibles localisés, le scraper extrait les champs utiles.
Il peut s'agir légendes, les notations, noms des auteurs, hashtags, Liens vers les médias, dates, texte de révision, ou d'autres attributs visibles.
Étape 4 : Nettoyage et structuration des résultats
Les données récupérées sont souvent désordonnées.
L'étape suivante consiste donc à normaliser les dates, à supprimer les caractères supplémentaires, à remodeler les champs et à convertir le tout en un fichier format structuré comme JSON ou CSV.
Étape 5 : Répétition du flux de travail à l'échelle
Si l'objectif est une collecte continue, le scraper s'exécute de manière répétée sur plusieurs pages, profils, flux ou URL sources. C'est là que la charge de maintenance commence à se faire sentir.
Étape 6 : Correction du flux de travail en cas de modification de la source
Un scraper dépend de la structure de la page. Si la plate-forme source modifie le mode de chargement des légendes, des vignettes ou des éléments de la page, le flux de travail peut échouer. Cet échec peut être mineur dans un rapport interne, mais il est beaucoup plus grave lorsque le résultat apparaît sur un site web public.
Dans ce cas, vous devez ajuster le racleur.
Exemple concret :
J'ai vu un flux de contenu social fonctionner parfaitement lors des tests, puis se dégrader discrètement après qu'une plateforme a modifié le mode de rendu des cartes multimédias. L'équipe n'a pas seulement perdu en qualité de données. Elle s'est retrouvée avec un site web défectueux.
Qu'est-ce qu'une API ?
Une API, ou interface de programmation d'applications, est un moyen officiel pour un système de demander des données à un autre système dans un format structuré.
‘Définition de ’API
Cette définition semble technique, mais la différence pratique est simple.
Avec le scraping, vous lisez ce qui apparaît sur la page. Avec une API, vous demander des données par le biais d'un canal conçu pour l'accès aux logiciels.
Au lieu d'analyser le contenu visible du front-end, vous recevez des données structurées directement à partir de points d'extrémité définis, souvent en JSON.
Cela facilite généralement la gestion du flux de travail.
Le les données sont plus propres, la structure est plus prévisible, et l'intégration dépend moins de l'aspect de la page dans le navigateur.
Bien entendu, les API ne sont pas parfaites. Elles peuvent comporter des limites, des approbations, des quotas et des règles contrôlées par le fournisseur concernant les données disponibles.
Mais pour les flux de travail récurrents, en particulier ceux qui sont liés à un site web en ligne, les API constituent généralement une base opérationnelle beaucoup plus solide.
Web scraping vs API : les principales différences en un coup d'œil
Lorsque les gens cherchent API vs web scraping ou web scraping vs. API, ils veulent généralement une comparaison rapide et pratique. Voici le cadre que j'utilise le plus souvent :
| Récupération de données sur Internet | API | |
|---|---|---|
| Source des données | Contenu visible de la page ou interface rendue | Critère d'évaluation officiel structuré |
| Format des données | Brut ou semi-structuré | Structuré et plus facile à intégrer |
| Fiabilité | Vulnérable aux changements de mise en page et de rendu | Généralement plus stable |
| Maintenance | Plus élevé | Plus bas |
| Clarté de la conformité | Moins prévisible | Généralement plus clair |
| Flexibilité | Élevé pour les pages publiques | Limité à ce que le fournisseur expose |
| Meilleure adéquation | Recherche, surveillance, extraction ponctuelle | Intégrations et flux de publication reproductibles |
| Adapté à la preuve sociale sur les sites web | Souvent fragile | Généralement bien meilleure |
La vraie différence entre le web scraping et l'API n'est pas seulement l'origine des données. C'est aussi la quantité d'efforts déployés après la collecte pour que le système reste utilisable, stable et prêt à être publié.
Avantages et inconvénients du web scraping
Étant donné que l'un des principaux mots clés de ce site est "pour et contre le web scraping", je souhaite montrer clairement ce compromis plutôt que de le simplifier à l'extrême.
| Les pros du web scraping | Les inconvénients du web scraping |
|---|---|
| Peut collecter des données publiques même s'il n'existe pas d'API | Ruptures en cas de modification de la mise en page ou du rendu |
| Très flexible et personnalisable | Nécessite une maintenance permanente |
| Utile pour le suivi, la recherche et l'écoute sociale | Peut faire face aux systèmes anti-bots et au blocage |
| Moins dépendant de la disponibilité de l'API du fournisseur | Le formatage des données est souvent incohérent |
| Utile pour les expériences légères | Peut créer un risque politique ou de gouvernance en fonction de l'utilisation |
| Peut capturer des champs visibles que les API n'exposent pas forcément | Faible adéquation avec les expériences de sites web soignés et orientés vers le client |
Je pense honnêtement que le scraping est souvent le plus efficace lorsque le résultat est interne. Dès que le résultat devient public et sensible à la marque, les faiblesses deviennent évidentes.
Avantages de l'utilisation des API
Si je devais résumer les principaux avantages de l'utilisation des API pour ce cas d'utilisation :
- Des données plus propres et structurées-par exemple, lorsqu'une marque tire et intègre les avis de Google par le biais d'une API, il peut recevoir le texte des commentaires, les évaluations par étoiles, les noms des auteurs et les horodatages dans un format prévisible au lieu de les assembler à partir d'éléments de page désordonnés ;
- Moins de dépendance à l'égard des présentations frontales-Par exemple, si une plateforme sociale redessine ses cartes de flux, une connexion basée sur l'API peut continuer à fonctionner parce qu'elle s'appuie sur le point de terminaison des données sous-jacentes plutôt que sur la structure visible de la page ;
- Mieux adapté aux flux de travail répétitifs-Par exemple, une entreprise implantée sur plusieurs sites peut collecter automatiquement des avis récents provenant de dizaines de sites dans un tableau de bord au lieu de vérifier manuellement chaque page une par une ;
- Soutien renforcé à la fraîcheur et à la cohérence-Par exemple, une marque de commerce électronique peut conserver les pages de produits. widgets d'évaluation mis à jour avec les commentaires récents des clients au lieu de laisser les mêmes témoignages statiques en place pendant des mois ;
- Une gouvernance et des règles d'accès plus claires-Par exemple, une équipe de marketing qui utilise des intégrations officielles a beaucoup plus de facilité à expliquer d'où vient le contenu et comment il est utilisé qu'une équipe qui s'appuie sur des pages publiques récupérées ;
- Moins de nettoyage et moins de réparations ultérieures-Par exemple, les développeurs n'ont pas à réparer les sélecteurs défectueux chaque fois qu'un site source modifie sa structure HTML ou le rendu des médias ;
- Un chemin plus facile de la collecte à la publication-Par exemple, une marque peut intégrer la preuve sociale provenant de sources connectées dans un carrousel de page d'accueil ou un widget d'avis en direct, sans avoir à assembler des outils de scraping web peu fiables.
En bref, les API ne se contentent pas de vous aider à collecter des données. Elles vous aident à construire un système autour de ces données. L'extraction des données devient un processus fiable qui fournit un accès structuré aux données.
De plus, les API vous permettent de cibler les pages d'un site web afin d'obtenir des données spécifiques au lieu de tout extraire de ces pages et d'en passer le contenu au crible.
Pourquoi les données des médias sociaux sont-elles différentes des données générales du web ?
La plupart des articles génériques sur le web scraping et les API traitent toutes les données en ligne comme si elles appartenaient à la même catégorie. D'après mon expérience, c'est là que l'analyse devient trop superficielle.
Le contenu des médias sociaux cesse d'être de simples données dès qu'il apparaît sur une page d'accueil, une page produit ou un widget d'évaluation. Il devient alors un contenu de confiance.
| Cas d'utilisation général des données web | Cas d'utilisation des données des médias sociaux |
|---|---|
| Souvent utilisé pour l'analyse interne | Souvent utilisé pour les preuves en contact avec la clientèle |
| Des problèmes mineurs de mise en forme peuvent être acceptés | La mise en forme affecte directement la perception |
| Un vide temporaire peut s'avérer gênant | Une rupture de flux peut nuire à la confiance |
| Généralement axé sur la récupération | Nécessite la récupération, la modération et la publication |
| Souvent sous forme de tableaux de bord ou de rapports | Vit sur les sites web, les widgets et les pages de conversion |
| Risque de marque plus faible en cas d'utilisation interne uniquement | Risque de marque plus élevé car les clients le voient |
C'est la raison pour laquelle je sépare si fortement ces cas d'utilisation. Une feuille de calcul peut tolérer des résultats désordonnés. Une feuille de calcul Widget UGC ne peut pas. Vous ne vous contentez pas d'extraire des données des pages web, vous les réimplantez dans des widgets de sites web vivants qui renforcent la confiance et se mettent à jour automatiquement.
Récupération de données de médias sociaux sur le web : Quels sont les points d'achoppement ?
L'attrait du web scraping des données des médias sociaux est évident au premier abord. Le contenu public semble accessible, la mise en place peut sembler rapide et les équipes peuvent croire qu'elles ont trouvé un raccourci.
Dans la pratique, le modèle commence à s'effondrer de manière prévisible :
Les changements au niveau de l'interface créent de la fragilité
Les plateformes sociales changent souvent.
Un flux qui dépend d'une structure de page visible peut cesser de fonctionner lorsqu'une légende se charge différemment, qu'un élément multimédia est restructuré ou que la plateforme modifie le mode de rendu de l'interface.
Conseil de pro :
Ne construisez jamais un flux destiné aux clients en vous basant uniquement sur des hypothèses de mise en page. Si une plateforme modifie le rendu des légendes, des cartes ou des médias, votre flux peut s'effondrer du jour au lendemain. C'est pourquoi l'accès officiel à l'API est généralement la base la plus sûre pour tout ce qui est en contact avec le public.
La qualité du formatage devient difficile à contrôler
Même lorsqu'un scraper fonctionne techniquement, le résultat peut ne pas être adapté à la publication.
J'ai vu des contenus sociaux récupérés avec des légendes manquantes, un mauvais rendu des médias, des mises en page de cartes inégales et des attributions incomplètes.
Conseil de pro :
Un flux qui “fonctionne techniquement” n'est pas la même chose qu'un flux prêt à être publié. Avant de mettre le contenu en ligne, assurez-vous que vous pouvez contrôler de manière fiable les légendes, la qualité des médias, l'attribution, la cohérence des cartes et le comportement de repli dans toutes les mises en page.
La modération devient un fardeau manuel
Une fois le contenu collecté, quelqu'un doit encore décider ce qui doit être mis en ligne.
Cela signifie que Gestion de l'UGC comme le filtrage du spam, la suppression des messages non pertinents, l'exclusion du contenu de faible qualité et la vérification de l'adéquation du résultat final à la marque.
Conseil de pro :
La collecte de contenu ne représente que la moitié du travail. Le véritable gain opérationnel réside dans l'intégration de flux de gestion du CGU pour filtrer les spams, supprimer les messages non pertinents, faire émerger le meilleur contenu et veiller à ce que chaque widget soit conforme aux normes de votre marque.
L'échelle multiplie les coûts de maintenance
Un aliment expérimental est gérable.
Les flux multiples à travers les pages de produits, les campagnes et les sites web des clients créent une charge de maintenance très différente. La collecte de données à grande échelle nécessite un accès API. Si vous voulez obtenir des données, des données fiables à grande échelle, vous devez avoir un accès direct à la disponibilité des données.
Conseil de pro :
Un flux expérimental peut être géré par le scraping, mais la collecte de données à grande échelle est une autre paire de manches. Lorsque vous avez besoin d'un contenu fiable sur plusieurs pages, campagnes ou sites de clients, l'accès direct à des données stables est bien plus important que la vitesse d'installation à court terme.
La gouvernance devient plus difficile à gérer
En fonction de la plateforme, du type de contenu et du cas d'utilisation, le scraping peut soulever des questions supplémentaires concernant les conditions, la vie privée, l'accès et le risque de marque.
Pour de nombreuses équipes, cette incertitude constitue à elle seule une base fragile pour la preuve de la relation avec le client.
Conseil de pro :
Si le contenu influence la confiance ou les décisions d'achat, la méthode de collecte doit être jugée en fonction de sa fiabilité et de sa gouvernance, et pas seulement en fonction de sa capacité à extraire les données une seule fois.
API directe ou API d'agrégation : quelle est la différence ?
C'est la distinction que la plupart des articles sur les API et le web scraping ne font pas. Beaucoup d'équipes pensent que le choix est simplement entre le scraping et l'utilisation d'une API.
En réalité, il est plus utile de faire une comparaison entre le scraping, l'intégration directe d'une API et un système de gestion de l'API. agrégateur de médias sociaux couche.
| Ce que vous obtenez | Principal inconvénient | Meilleure adéquation | |
|---|---|---|---|
| Récupération de données sur Internet | Accès flexible au contenu public visible | Fragile, lourd à entretenir, désordonné pour la publication | Recherche, suivi, expériences |
| Intégration directe de l'API | Accès officiel structuré aux données sources | Vous devez toujours mettre en place une logique de modération, de synchronisation, de formatage et de publication. | Équipes techniques disposant de ressources de développement |
| API ou plateforme d'agrégation | Accès officiel et outils de flux de travail, de modération, d'organisation et de publication | Moins de contrôle brut que les systèmes entièrement personnalisés | Marques, spécialistes du marketing, agences, équipes de commerce électronique |
L'accès direct à l'API est puissant. Mais de nombreuses équipes sous-estiment ce qui vient après la connectivité. Une fois que vous avez les données, vous devez encore gérer les sources, les règles de modération, la logique de transformation, les cycles de rafraîchissement, la génération de widgets, le contrôle de la mise en page et l'entretien continu.
C'est pourquoi je reviens toujours au même point : l'accès brut n'est pas la même chose qu'un pipeline de preuve sociale fonctionnel. Vous avez besoin d'un agrégateur de médias sociaux comme EmbedSocial.
Quand le web scraping a-t-il encore un sens ?
Je ne pense pas qu'un article crédible sur le web scraping par rapport à l'API doive prétendre que le scraping n'a pas sa place. C'est tout à fait le cas. Un bon exemple est écoute sociale.
Si une équipe souhaite surveiller les conversations publiques, explorer les discussions visibles ou recueillir des données pour une analyse interne, le scraping peut s'avérer pratique et efficace.
Un autre exemple est le créneau public la collecte de données.
Parfois, les informations nécessaires sont publiques, mais il n'existe pas d'API utile. Dans ce cas, le scraping peut être le seul moyen réaliste d'accéder aux données.
Je pense également que le raclage peut être utile dans les cas suivants des expériences internes légères.
Si le flux de travail est temporaire, que l'équipe comprend sa fragilité et que rien de ce qui est en rapport avec le client n'en dépend, le compromis peut être acceptable.
Mais une fois que le contenu fait partie de l'expérience de la marque publique, je conseille généralement aux équipes d'élever le niveau. C'est à ce moment-là que le scraping commence à devenir un handicap.
Pourquoi l'agrégation sociale basée sur une API est-elle le meilleur système à long terme pour les marques ?
C'est là que l'analyse de rentabilité devient beaucoup plus claire. Un modèle d'agrégation basé sur une API est meilleur pour les marques parce qu'il résout plus que la question de la collecte.
Il permet de gérer le cycle de vie complet du contenu après sa collecte.
Prenons l'exemple d'une marque de commerce électronique en pleine expansion.
Il peut s'agir d'avis récents sur les pages de produits, d'UGC sur les pages de renvoi et de preuves sociales sur la page d'accueil. Essayer de maintenir tout cela à travers des solutions de contournement éparses crée très rapidement des problèmes. L'agrégation centralisée, basée sur une API, rend ce système gérable.
Une entreprise de services est un autre bon exemple.
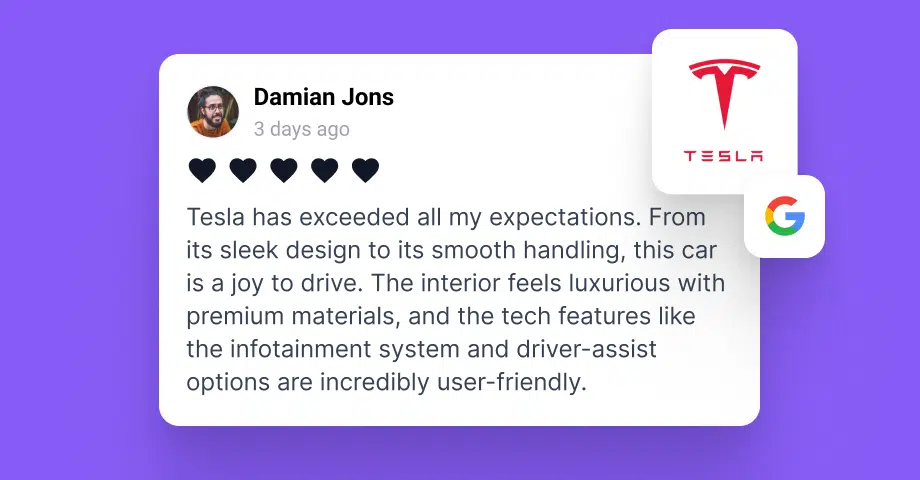
Remplacer les captures d'écran de témoignages statiques par du contenu d'évaluation en direct peut rendre le site plus actuel, plus crédible et plus en phase avec ce que les clients disent en ce moment même. Imaginez un site mur d'amour sur votre site web qui se met à jour automatiquement.
Je m'intéresse également à la quantité de travail qu'un système génère en coulisses. Un bon flux de travail réduit les captures d'écran, la curation manuelle, les tickets de développement répétitifs et les corrections d'urgence.
Exemple tiré de mon travail à EmbedSocial :
J'ai vu des entreprises remplacer un bloc de témoignages obsolète par un flux en direct d'avis Google récents et de mentions sociales. Le résultat n'était pas seulement un contenu plus frais. Le site semblait plus actif, plus actuel et plus crédible.
Comment EmbedSocial transforme la preuve sociale en un actif vivant pour le site web ?
C'est la partie que je connais le mieux grâce à mon expérience pratique.
Au EmbedSocial, L'objectif n'est pas seulement d'aider les marques à collecter du contenu. Il s'agit de les aider à transformer le contenu réel des clients en quelque chose d'organisé, de modéré et de prêt à être publié.
Voici un graphique simple qui illustre le processus d'agrégation du contenu des médias sociaux :

Et voici les étapes que vous devez franchir ensuite créer votre compte EmbedSocial:
Étape 1 : Soumettre une demande de conception de widget AI
Tout d'abord, vous devez demander à l'éditeur de widgets AI de créer votre nouveau widget de médias sociaux :

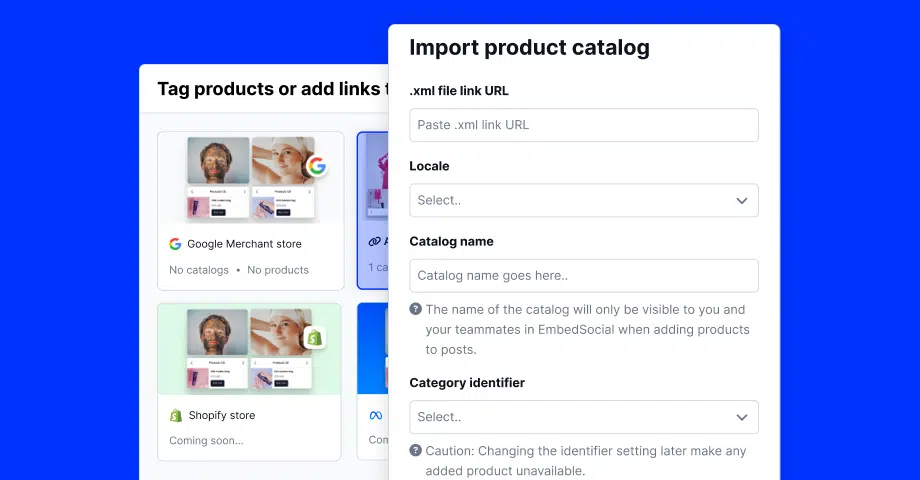
Étape 2 : Connectez votre ou vos sources de médias sociaux
Ensuite, vous devez vous connecter à vos médias sociaux pour extraire leur contenu dans EmbedSocial :

Étape 3 : Concevoir et personnaliser votre widget
Vous pouvez ensuite sélectionner votre modèle de widget et le personnaliser davantage à l'aide d'invites AI :

Si vous n'êtes pas satisfait de l'aspect du widget, il vous suffit de naviguer vers la conception AI et d'ajouter d'autres invites :

Étape 4 : Modérer le contenu de votre widget
Rendez-vous sur le site La modération pour sélectionner les articles que vous souhaitez mettre en avant :

Étape 5 : Publier les widgets sur le site web
Une fois que le widget ou le flux est prêt, vous devez copier son code intégrable via la fonction Embarquer tabulation :

Étape 6 : Collez le code du widget sur votre site web
La dernière chose à faire est de naviguer vers votre constructeur de site web et de coller le code du widget.
Voici comment cela fonctionne pour tous les constructeurs de sites web les plus populaires :
Comment intégrer des CGU sur WordPress ?
Voici comment intégrer des contenus UGC sur les sites WordPress :
- Une fois que vous avez créé votre widget EmbedSocial, rendez-vous sur votre page d'administration WordPress ;
- Connectez-vous à votre compte et ouvrez la page où vous souhaitez ajouter le widget UGC ;
- Cliquez sur le bouton + bouton dans l'éditeur et choisissez HTML personnalisé pour coller le code du widget ;
- Cliquez "Économiser" lorsque vous avez terminé.

Comment intégrer des contenus UGC sur Shopify ?
Voici comment intégrer des contenus UGC sur les sites Shopify :
- Connectez-vous à votre compte Shopify après avoir copié le code du widget intégrable dans EmbedSocial ;
- Naviguez jusqu'à la page Pages et cliquez sur Ajouter une page;
- Dans le cadre de la Contenu le code incorporable ;
- Sélectionnez la page où vous souhaitez que le code apparaisse et appuyez sur Sauvegarder.

Comment intégrer des contenus UGC sur Squarespace ?
Voici comment intégrer des contenus UGC sur les sites Squarespace :
- Copiez le code de votre widget EmbedSocial et connectez-vous à votre compte Squarespace ;
- Choisissez la page sur laquelle vous souhaitez que les avis apparaissent ;
- Cliquez sur Ajouter une nouvelle section et ensuite Ajouter un bloc à l'endroit où vous souhaitez afficher le widget ;
- Dans la liste des blocs, sélectionnez Emboîter‘ ;
- Cliquez sur le bloc, sélectionnez ‘Extrait de code", et cliquez sur ‘Intégrer les données" ;
- Enfin, dans la boîte de code, collez le code de révision copié ;
- Veillez à enregistrer et à publier vos modifications sur Squarespace.

Comment intégrer un contenu UGC sur Wix ?
Voici comment intégrer des contenus UGC sur les sites Wix :
- Connectez-vous à votre éditeur Wix et choisissez la page et l'emplacement pour ajouter le widget ;
- Cliquez sur le bouton Icône "+" (+) dans le coin supérieur gauche pour ajouter un nouvel élément ;
- Trouver le Embed & Social et tapez Code d'intégration;
- Collez le code et appuyez sur Mise à jour.

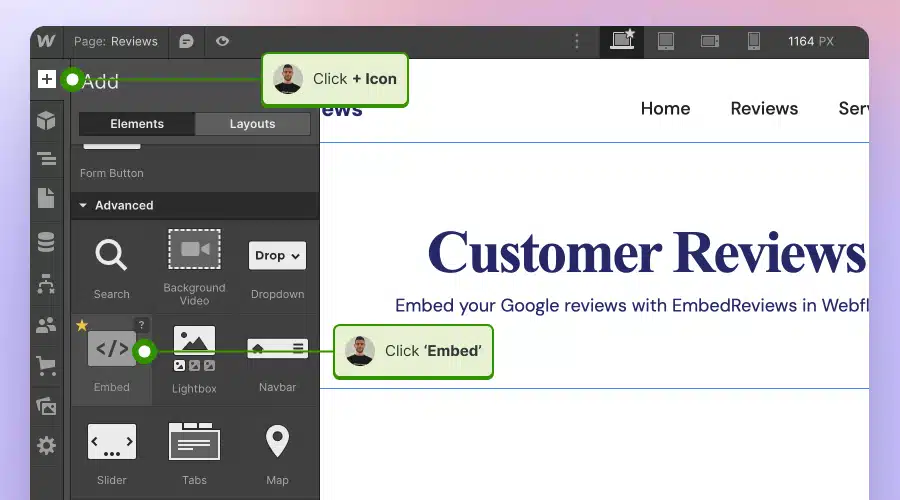
Comment intégrer un contenu UGC dans Webflow ?
Voici comment intégrer des contenus UGC sur les sites Webflow :
- Après avoir créé le widget dans EmbedSocial, connectez-vous à votre compte Webflow ;
- Allez dans la vue d'édition de votre site web dans Webflow ;
- Choisir de Ajouter un élément dans Webflow et sélectionnez l'option Élément "Embed;
- Faites-le glisser et déposez-le à l'endroit où vous souhaitez que vos commentaires apparaissent ;
- Dans le champ de saisie, collez le code EmbedSocial copié.
Comment intégrer un contenu UGC sur Pagecloud ?
Voici comment intégrer des contenus UGC sur les sites Pagecloud :
- Après avoir copié le code EmbedSocial, connectez-vous à votre Pagecloud compte ;
- Commencez à modifier la page web où vous souhaitez que les commentaires apparaissent ;
- Tapez sur Apps dans le menu du ruban de gauche et sélectionnez Embed' (Intégrer);
- Collez le code EmbedSocial dans le champ popup et cliquez sur Ok pour terminer le processus.

Comment intégrer des contenus UGC sur Google Sites ?
Voici comment intégrer des contenus UGC sur Google Sites :
- Une fois que vous avez copié le code de votre widget intégrable dans EmbedSocial, connectez-vous à votre compte Google Sites ;
- Naviguez jusqu'à la page où vous souhaitez intégrer le widget ;
- Utiliser le Onglet "Insérer dans Google Sites et choisissez l'endroit où vous souhaitez placer le widget ;
- Choisir 'Embarquer' dans le menu et collez le code copié dans la boîte de dialogue ;
- Cliquez sur 'Suivantet ensuiteInsérer' pour finaliser l'intégration.

Comment intégrer des contenus UGC dans Elementor ?
Voici comment intégrer des contenus UGC dans Elementor :
- Connectez-vous et accédez à la page où vous souhaitez ajouter les commentaires ;
- Appuyez sur une section vide et choisissez l'option Bloc "HTML dans la section gauche du ruban ;
- Faites-le glisser et déposez-le sur la page et collez le code du widget dans le champ vide ;
- Mettez à jour et publiez la page pour voir le widget en direct.

Comment intégrer l'UGC dans Notion ?
Voici comment intégrer des contenus UGC dans Notion :
- Après avoir copié le code du widget, se connecter à Notionet accéder à la page correspondante ;
- Tapez le /embed et, dans le menu déroulant, choisissez la commande Option "Embed" (intégrer);
- Collez l'URL et cliquez sur le lien "Embed link" (lien intégré) pour ajouter vos commentaires à Notion.

Comment intégrer des CGU sur des sites web HTML ?
Voici comment intégrer le CGU dans les sites HTML
- Copiez la revue du widget EmbedSocial à partir de la section Onglet "Embed dans le coin supérieur gauche de l'éditeur ;
- Ouvrez le fichier HTML de votre site web, qu'il s'agisse d'une nouvelle page ou d'une page existante ;
- Collez le code d'intégration EmbedSocial copié à l'endroit où vous souhaitez que les commentaires s'affichent.

Conclusion : Utilisez des plateformes UGC avec accès API pour construire un flux de travail fiable en matière de preuve sociale !
La raison pour laquelle la question du web scraping par rapport à l'API reste si fréquente est simple : les deux méthodes peuvent aider à collecter des données en ligne. Mais pour les marques, ce cadre est encore trop étroit.
La meilleure question est de savoir comment transformer le contenu des médias sociaux en une expérience stable, digne de confiance et orientée vers le client, qui permette au site web de conserver sa fraîcheur au fil du temps.
De mon point de vue, le scraping a toujours sa place dans la recherche, le suivi et l'analyse exploratoire. Mais lorsque l'objectif est de publier une preuve sociale sur un site web, un flux de travail d'agrégation basé sur une API est généralement la solution la plus intelligente à long terme.
Cette approche vous donne plus qu'un accès.
Il vous offre une structure, une modération, une cohérence et un chemin réaliste pour passer d'un contenu client éparpillé à des widgets de site web vivants qui renforcent réellement la confiance.
FAQ sur le web scraping et l'API pour le contenu des médias sociaux
Quelle est la différence entre l'utilisation d'une API et le web scraping ?
La principale différence entre le web scraping et l'API réside dans la manière d'accéder aux données.
Le web scraping permet d'extraire des informations de ce qui apparaît sur une page web, tandis qu'une API fournit des données structurées par le biais d'un point d'accès officiel conçu pour l'intégration de logiciels.
L'utilisation d'une API est-elle préférable au web scraping ?
Lorsque les équipes comparent API et web scraping, la réponse dépend du cas d'utilisation.
Pour la recherche ou le suivi ponctuel, le scraping peut s'avérer judicieux. Pour les flux de travail répétitifs et le contenu des sites web destinés aux clients, les API sont généralement le meilleur choix.
Qu'est-ce que le web scraping en termes simples ?
Si je devais répondre à la question de savoir ce qu'est le web scraping en une phrase, je dirais qu'il s'agit du processus de collecte automatique d'informations visibles sur les pages web et de leur transformation en données structurées.
C'est pourquoi il est souvent utilisé dans les processus de surveillance, de collecte de données publiques et de recherche.
Comment fonctionne le web scraping étape par étape ?
Au niveau de base, le fonctionnement du web scraping suit une séquence.
Un scraper demande une page, lit le contenu HTML ou rendu, identifie les éléments cibles, extrait les champs nécessaires et les enregistre dans un format structuré tel que JSON ou CSV.
Quels sont les avantages et les inconvénients du web scraping ?
Les principaux avantages et inconvénients du web scraping se résument à la flexibilité par rapport à la fiabilité.
Le scraping est flexible car il permet de collecter des données publiques même lorsqu'il n'existe pas d'API, mais il est également plus fragile, plus lourd en termes de maintenance et généralement moins adapté aux expériences de sites web en contact avec les clients.
Quels sont les principaux avantages de l'utilisation des API ?
Les principaux avantages de l'utilisation des API sont la structure, la cohérence et la reproductibilité.
Les API renvoient généralement des données plus claires, dépendent moins des modifications apportées aux pages d'accueil et sont plus faciles à connecter à des flux de travail à long terme.
Peut-on utiliser le web scraping pour les données des médias sociaux ?
Oui, il est possible, dans certaines situations, de récupérer des données de médias sociaux sur le web.
Mais d'après mon expérience, elle est beaucoup moins fiable lorsque l'objectif est de publier ce contenu sur un site web en ligne où le formatage, la fraîcheur et la modération sont des éléments importants.
Pourquoi les flux sociaux récupérés sont-ils si souvent interrompus ?
Les flux récupérés sont souvent interrompus parce qu'ils dépendent de la structure de la page.
Si une plateforme modifie le rendu des légendes, des vignettes, des cartes multimédias ou d'autres éléments, le scraper peut cesser de renvoyer des données complètes ou cohérentes.
Quand le web scraping a-t-il encore un sens ?
Le web scraping reste utile pour la recherche, l'écoute sociale, la collecte de données publiques et certaines expériences internes.
Je suis beaucoup plus prudent lorsque le contenu est destiné à une expérience de marque en contact avec le client.
Quelle est la différence entre une API directe et une plateforme d'agrégation ?
Une API directe vous donne un accès brut aux données sources.
Une plateforme d'agrégation prend cet accès et le transforme en un flux de travail utilisable en vous aidant à collecter, modérer, organiser et publier du contenu à partir de sources multiples.
Puis-je afficher le contenu des médias sociaux sur mon site web sans faire de scraping ?
Oui.
En fait, pour la plupart des marques, c'est la meilleure solution. Un flux de travail d'agrégation basé sur une API vous permet de collecter des preuves sociales par le biais de connexions officielles et de les publier dans des widgets, des carrousels, des galeries ou des flux d'avis sans avoir recours à des méthodes de scraping fragiles.
Le web scraping est-il moins cher que les API ?
Pas toujours.
Le scraping peut sembler moins cher à première vue, mais la charge de maintenance à long terme modifie souvent le tableau des coûts une fois que les correctifs, le suivi, les problèmes de formatage et les pannes de l'interface publique sont ajoutés.
L'agrégation de médias sociaux basée sur une API est-elle meilleure pour les marques ?
Pour la plupart des marques, oui.
Lorsque l'objectif est de maintenir un site web à jour avec un contenu client fiable, l'agrégation basée sur l'API est généralement le meilleur système à long terme car elle prend en charge la collecte, la modération et la publication en un seul flux de travail.